Tesseræ

Tessera / æ - why? Link to heading
Just like Geosketching was responding to a practical need I had in sharing and discussing basic geospatial data, it is a long time I am not too happy with the dominating paradigm in note taking, brainstorming, and documentation development, particularly at early stage. Thus, briefly:
Again.. Problem Link to heading
Sometimes I have to:
- Brainstorm
- Design some initial slide deck structure - Note: slide sorter / lighttable and slide editing in most (any) presentation framework are mutually exclusive
- Create an embryonal set of (linked) documents
Yes, there is Obsidian (and plugins), and all sort of text editors. There are tabs yes, but they are not very synoptic.
What follows is a solution that works for me, and perhaps for a few others, too.
The actual trigger for Tessera was collecting information and documenting within a Remote Sensing-based applied science project at Earthgraph. The context does not matter though, as the same early idea recording/structuring process is very general.
Solution Link to heading
A note is an individual file. Multiple notes, with a file each, and their order is simply recorded inside a json, as well as eventual tags (that can be externally machine-digested, should that be needed).
i.e.
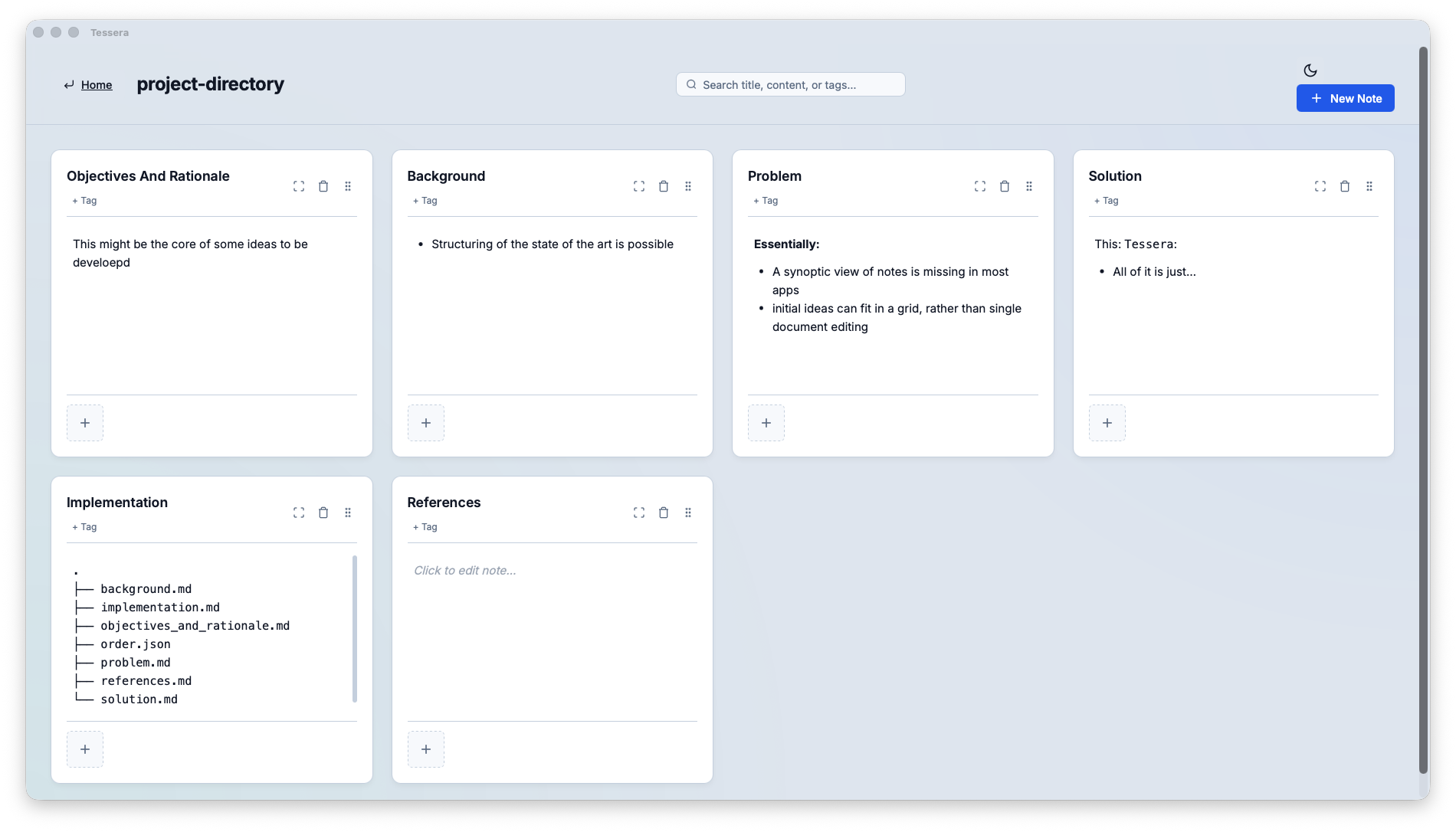
all of that is simply:
.
├── background.md
├── implementation.md
├── objectives_and_rationale.md
├── order.json
├── problem.md
├── references.md
└── solution.md
It is just very basic, and pasting images results in an image file saved inside the directory named like its note, e.g.
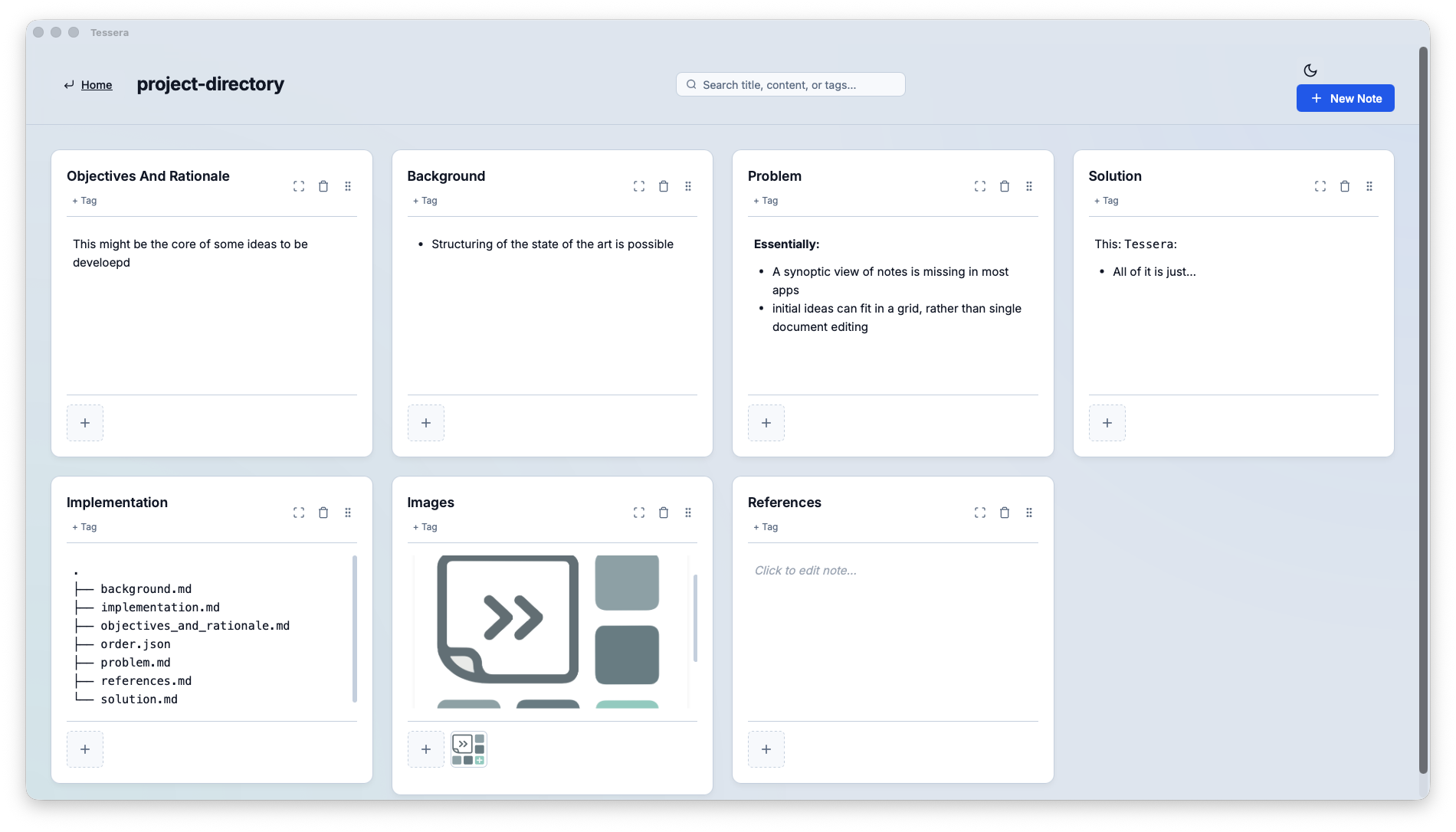
which is made of:
.
├── background.md
├── images
│ └── img_1773920944489_image.png
├── images.md
├── implementation.md
├── objectives_and_rationale.md
├── order.json
├── problem.md
├── references.md
└── solution.md
It is not a slide deck editor, not quite. But it does serve a related task: Collecting materials for preparing a slide deck, whether it’s Powepoint, Keynote, or Reveal. Dumping text and images in those systems is not very transparent. And finding each and every asset again is another story.
So, you can see Tessera also as a very poor-man asset management for low-complexity content, i.e. text, and images, to a certain extent. Basic, minimalistic, and optimally per project (unlike the typical use of Obsidian).
Notational velocity and nvalt (as well as deft for Emacs), and many others are - in my view - what should be meanwhile the default for instant search, retrieval, creation. They are not, unfortunately. Thus, the behavior of Tessera is intentionally a bit nvalt-y with a simple search bar.
Tessera is not meant to be an extensive note taking system, and it can very much just “plug” into any existing directory, or vault.
Use cases Link to heading
Use cases I originally envisaged are just a subset. But to put them down:
- Early iteration on ideas.
- Pitch conception and early preparation.
- Poor-man minimalistic asset management (text, images) for collecting presentation, pitch materials.
- Structured impromptu note taking for a group (e.g. by a chair/lead/moderator collecting inputs, displaying the process on a wide screen, or projector, for later refinement, processing, wiki ingestion, and alike).
The latter brings in also the topic of web apps (maybe, one day). Which is a fair point, but local-first, human-first embryonal knowledge generation is the main task of Tessera.
Humans, et al. Link to heading
What is now possible with a Shoggoth is quite remarkable, in terms of speed of execution. Yes, that does not save necessarily much time in figuring things out, and fixing them, but, it does make ideas implemented at unprecedented speed.
Tesserae are plain text, and (for now) a simple 1-degree-nested directory tree, and a pair of json files to clarify order and tags. All very much edible for current LLM-based agents.
In order to make this work, there is also a Tessera SKILL.md. It has been tested with Claude, Cursor, and local Ollama-based agents. Results are mixed, but the simplicity of Tessera (just markdown files and a couple of json) makes it very accessible even for not very capable agents (it might very well be that a SKILL.md is not even needed…).
The very first attempt to use the above skill with a modest local ollama model (gemma4:e2b) is documented in this gist, including my typos.
Finally, this is not yet tested (but it should be easy to): Since it’s such a simple directory structure, having it git-controlled can reconstruct the time series of the notes, potentially (as well as separating human from agent inputs, if commits are appropriately tagged, perhaps), thus making the Tessera evolution at least a bit auditable.
I stress that the main use case is human in nature. Agents in the loop are at the moment a divertissement only. The capability is there, though. The fact that it is there does not mean of course that it is advised to use it: Tessera is primarily to help humans putting down their ideas.
Icon generation Link to heading
The idea was clear, some flashcard-like, ordered, tagged post-it that can be edited together, rather than one by one. The icon design followed. Yes, lazily I started with a cloud Shoggoth, i.e. first step below. But then went the old way, by hand.
This is the icon time series:
![]()
If you see it in action, the icon might make a little more sense…
Tessera in action Link to heading
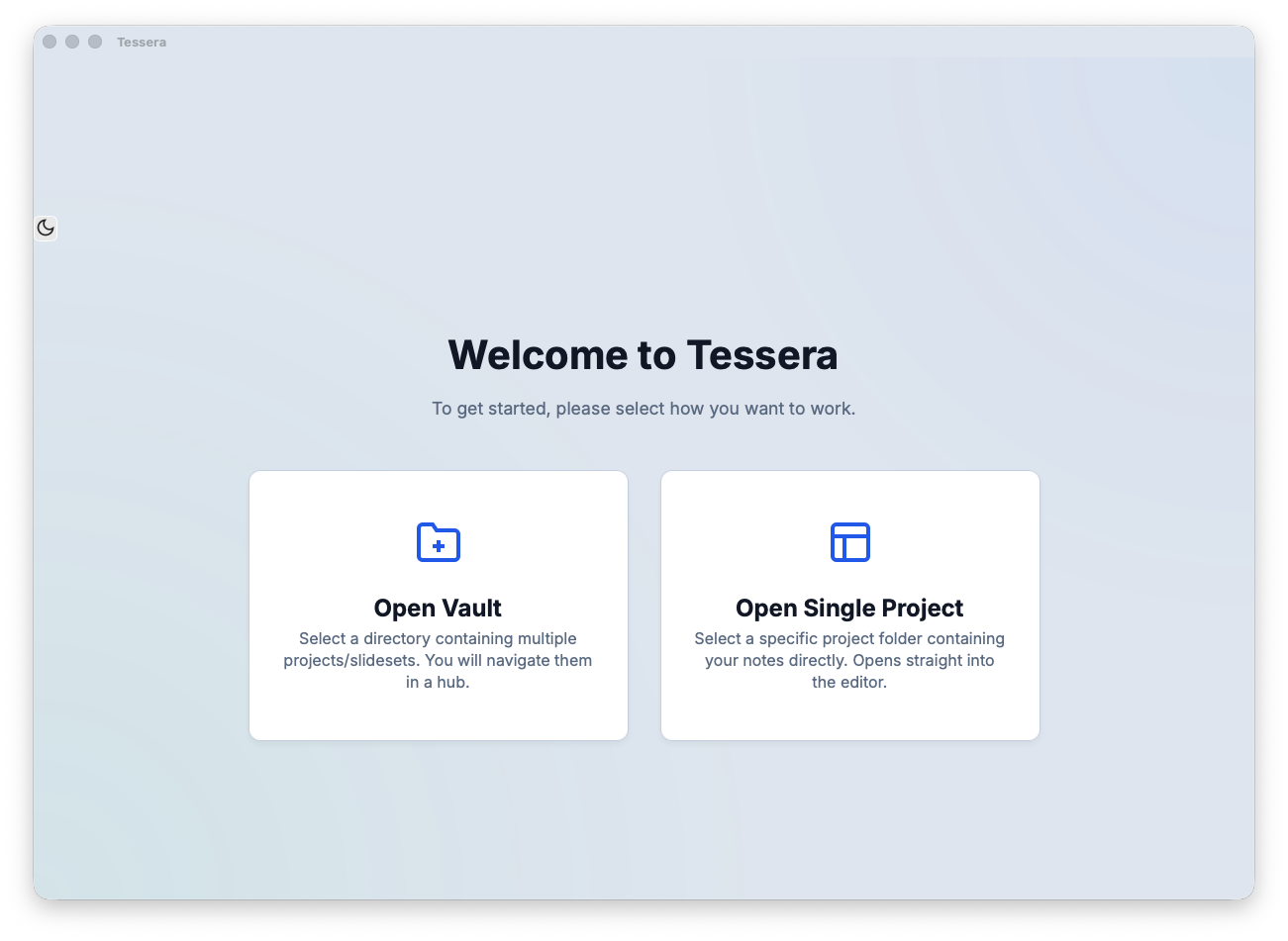
Optimally each set of Tesserræ should sit in the relevant project directory (my preferred use case), meaning that the size of it does not grow too large. One can choose to have a vault, and structure it in subdirectories, but that is just not my preference.
Complex starts with simple and one does not need nowadays to delegate idea conception to an AI agent (they might help along the way). Tessera might actually help during such conception, even if some bits of the app might still be a bit basic.
To close, Tessera does very little, but that little is essential: It helps with idea generation, before crystallisation, further development, and increase in complexity.

Acknowledgements Link to heading
I thank my current set of Shoggoths, and a number of colleagues who were kind enough to test, and provide encouragement, and feedback, in particular MN, ARM, SVG, TH.
You can grab the source code on Earthgraph’s Github, at: https://github.com/earthgraph/tessera/. Binaries will be also made available eventually, but for now, it’s more of a geek testing ground. See also https://tessera.earthgraph.eu/.